![]() 3.0 Model Framework
3.0 Model Framework
3.1 Objectives
3.2 Approach
3.3 Requirements
3.4 Design
3.5 Data Exchange Protocol
3.5 Data Exchange Protocol
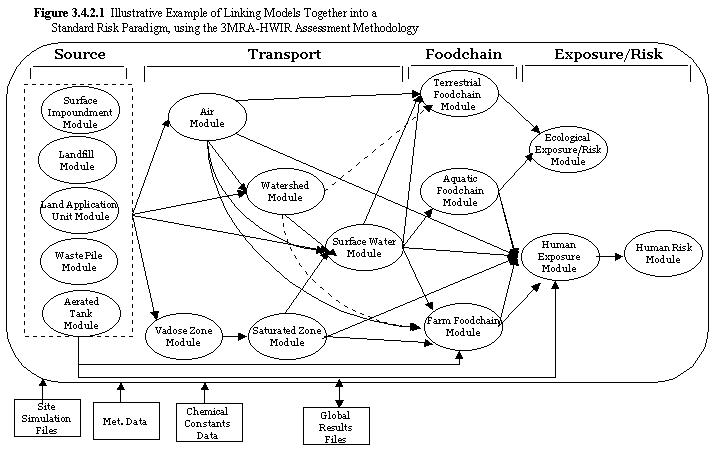
In the past, the traditional approach for linking models was to directly connect (i.e., hard-wire) module types (e.g., aquifer models to river models). Each connection specifically reflected the data needs of the consuming model, resulting in an efficient transfer of data but also resulting in a confusing model structure, difficult to manage and update. Under the traditional approach, if a user wanted the ability to link several models of a certain type (e.g., 1-dimensional, 2- dimensional, and 3- dimensional aquifer models) to several models of a different type (i.e., 1- dimensional, 2- dimensional, and 3- dimensional river models), each model was directly linked (i.e., hard-wired) to each other through a processor. With this approach, a user could choose to link any one of the aquifer models to any one of the river models. The following figure illustrates the traditional approach for linking models (i.e., module types in the figure) and data transfer. This linkage scheme is very efficient and exact, allowing for direct communication between models and providing an environment for dynamic feedback between models. Unfortunately, as illustrated by the figure, this scheme can become extremely complicated and unmanageable and does not allow the user to add new models, parameters, data requirements, databases, etc. to the system without having to modify the entire system and revamp legacy models.
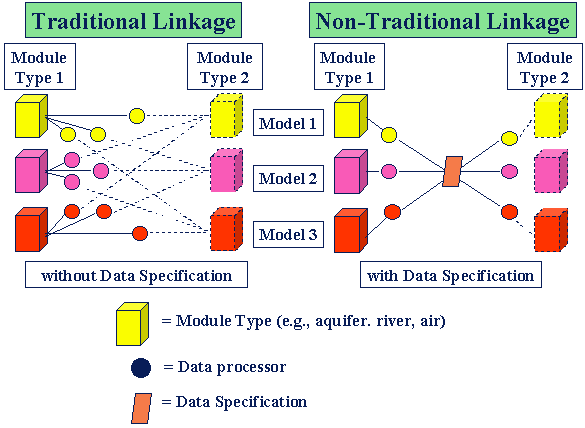
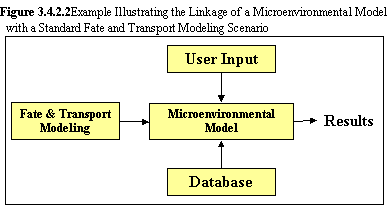
With the advent of "object-oriented" modeling concepts, each of the models, which enters into the system, agrees on a data exchange protocol. The non-traditional approach identifies system data specifications to which models adhere when passing information between model types and databases, as illustrated in the above figure. Pre- and post-data processors allow legacy models to remain unaffected and facilitate the ability to "plug" legacy models directly into the system, enhance quality control, and simplify management of and modifications to multiple models. This Plug & Play attribute is an extremely powerful and desirable feature, as it allows users and model developers to insert the most appropriate models to meet specific needs.
Data specifications between communicating models represent the contract between what the upstream model produces (e.g., aquifer model) and what the downstream model consumes (e.g., river model). The data specification is similar to the telephone numbers in a telephone book. Both parties agree to the telephone numbers, and, when each wants to communicate, they do so using the appropriate telephone number (see the following figure). Each year the telephone books are updated (see the following figure); as such, the design of the CCEF must accommodate new models, data requirements, parameters, and linkages but still maintain backward compatibility with existing models in the system.

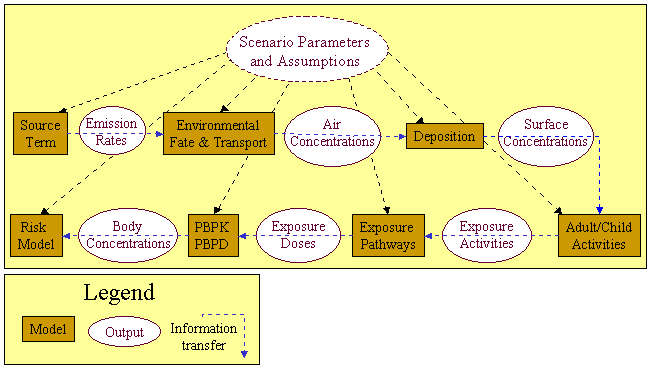
As noted earlier, the fundamental responsibility of the Framework is associated with the arrows that connect the models and databases, as illustrated in the figures below and in the model flow diagrams for scenario 1, scenario 2, scenario 3 and scenario 4. Those arrows represent the transfer of information from one component to another. The system is charged with managing model and database linkages, the firing sequence of the models, and data transfer between components. The system is not responsible for what happens within the models. The key to a successful transfer is to ensure that the producing component provides information that meets the needs of the consuming component and that the information is in a form that is recognizable by both components. This shared responsibility for managing data transfer is based on datasets, whose metadata information is described by Data Dictionary File.